
Devisa Use Cases
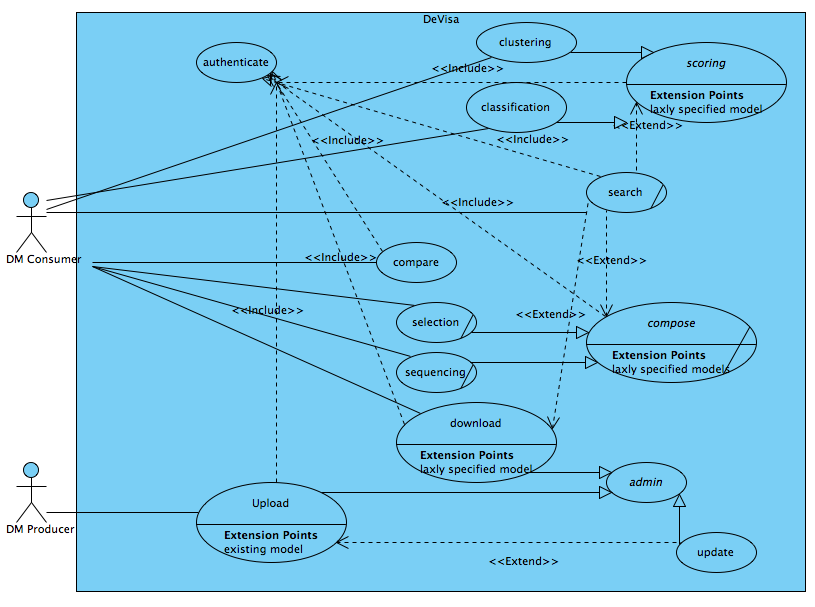
Summary
| Name | Documentation |
 DM Consumer
DM Consumer
|
The DM Consumer is a WS client application that uses DeVisa DM models. |
 download
download
|
A DM Consumer can download a DeVisa model in order to use it internally, e.g import into the DM application. |
|
authenticate
|
The WS client that invokes a certain method might need to be authenticated in order to execute the required function. |
|
admin
|
The Admin use case involves uploading/downloading the DeVisa models without any other processing. |
|
replace
|
Replace occurs when a model is replaced completely by a newer one. The new model will get the same model ID in the repository. |
|
upload
|
A DM Producer can upload models in the DeVisa repository via WS methods (SOAP, XMLRPC). |
|
update
|
Update occurs when a model needs only a certain type of adjustment. This use case should use a specific XML update technique. The update procedure is triggered by the system itself in most of the cases. |
|
search
|
The searching functions allow inspecting the properties of the PMML models in the repository. The search functions conform and therefore are limited to the information that a PMML model can incorporate according the PMML 3.2 specification. DeVisa provides searching functions such as:
Selecting the models with desired properties
Selecting the models that conform to a certain schema
This type of search is used especially as an extension to the scoring use care
Full text search in the model repository This type of search is useful when the client is looking for keywords in the description of the model, in the field names or field description, in the function type etc
Future work: create a search mechanism that allows more complex predicates on the search criterions. |
|
scoring
|
The scoring use case means applying the models on the new instances. The scoring occurs via web service methods. Depending on the models, there are several types of DeVisa scoring procedures:
|
|
classification scoring
|
The scoring method receives as input a set of instances and one or more classification models and classifies the instances with respect to the models. |
|
clustering scoring
|
The scoring method receives as input a set of instances and one or more clustering models and assigns the instances to the most appropriate cluster in each of the models. |
|
association rules scoring
|
The scoring method receives as input a set of items (instances) and one or more association rule models. It determines all rules of each of the input models whose antecedent itemset is a subset of a the input itemset and returns the consequents of these rules as the inferred itemsets. An extension of this procedure computes all rules whose antecedent and consequent itemsets are included in the input itemset. This version is useful to determine which itemsets support which rules. |
|
compose
|
Model Composition allows the combination of simple models into a single composite PMML model. PMML version 3.2 supports the combination of decision trees and simple regression models. More general variants would be possible and may be defined in future versions of PMML. In PMML Model composition uses three syntactical concepts
In DeVisa simple models can be combined into more complex ones forming new valid PMML documents. A client application can specify the models subject to composition and the combination method. DeVisa identifies the specified models. If the models do not exist in the repository then the process stops. The found models are checked for compatibility. If they are not compatible the process stops. The new valid model is returned to the user/stored in the repository. |
|
sequencing
|
Model sequencing is the process through which two or more models are combined into a sequence where the results of one model are used as input in another model. Model sequencing is supported partially by the PMML specification. Examples of sequencing:
|
|
selection
|
Model selection in PMML allows for combining multiple 'embedded models', aka model expressions, into the decision logic that selects one of the models depending on the current input values. Examples of selection
|
|
compare
|
A client application (DM Consumer) wants to compare two models. The client needs to specify:
Syntactic Comparison. Two PMML models are compared through a XML differencing approach. To be researched if the eXist's XML diff extension module can be used here. Semantic Comparison. Two models can be compared from the following points of view:
The Semantic comparison is useful for the cases in which the client envisions a model composition and wants to pre-check the compatibility of the models |
|
statistics
|
An application can invoke this service to obtain statistics on the models. Example of statistics:
At the beginning DeVisa should be able to provide only a full report (PMQL) for the point (1). |
|
DM Producer
|
The DM Producer is a WS client application -typically a DM application, like Weka- who uploads models in the DeVisa Repository. |
 DeVisa
DeVisa
|
Details
DM Consumer
| Name | Value |
| Visibility | public |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | The DM Consumer is a WS client application that uses DeVisa DM models. |
| Business Model | false |
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
download
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | A DM Consumer can download a DeVisa model in order to use it internally, e.g import into the DM application. |
| Rank | High |
| Business Model | false |
| laxly specified model |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Extend | |
| To |
search
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Unamed Generalization | |
| From |
admin
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
authenticate
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | The WS client that invokes a certain method might need to be authenticated in order to execute the required function. |
| Rank | Medium |
| Business Model | false |
| Unamed Include | |
| From |
scoring
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Include | |
| From |
compare
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Include | |
| From |
compose
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Include | |
| From |
upload
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Include | |
| From |
download
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Include | |
| From |
search
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Include | |
| From |
statistics
|
| Visibility | Unspecified |
| Stereotypes | Include |
admin
| Name | Value |
| Abstract | true |
| Leaf | false |
| Root | false |
| Documentation | The Admin use case involves uploading/downloading the DeVisa models without any other processing. |
| Rank | Unspecified |
| Business Model | false |
| Unamed Generalization | |
| To |
replace
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Generalization | |
| To |
upload
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Generalization | |
| To |
download
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Generalization | |
| To |
update
|
| Substitutable | false |
| Visibility | Unspecified |
| Admin | |||||||
| Super Use Case | |||||||
| Author | dianagorea | ||||||
| Date | Jan 17, 2008 2:19:00 PM | ||||||
| Brief Description | The DM client uploads/downloads the DeVisa models without any other processing. | ||||||
| Preconditions | |||||||
| Post-conditions | |||||||
| Flow of Events |
|
||||||
replace
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation |
Replace occurs when a model is replaced completely by a newer one. The new model will get the same model ID in the repository. |
| Rank | Medium |
| Business Model | false |
| Unamed Extend | |
| From |
upload
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Unamed Generalization | |
| From |
admin
|
| Substitutable | false |
| Visibility | Unspecified |
upload
| Name | Value |
| Abstract | false |
| Leaf | false |
| Root | false |
| Documentation |
A DM Producer can upload models in the DeVisa repository via WS methods (SOAP, XMLRPC). |
| Rank | High |
| Business Model | false |
| existing model | |
| Documentation | If the model that the DM producer has uploaded already exists in the DeVisa repository then and the model is newer than the existing one then it is replaced. |
| Unamed Extend | |
| To |
replace
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Generalization | |
| From |
admin
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Upload | |||||||||||||
| Super Use Case | admin | ||||||||||||
| Author | dianagorea | ||||||||||||
| Date | Jan 17, 2008 3:04:44 PM | ||||||||||||
| Brief Description | |||||||||||||
| Preconditions | The DM producer has a model expressed in PMML | ||||||||||||
| Post-conditions | The model is stored in DeVisa PMML repository. | ||||||||||||
| Flow of Events |
|
||||||||||||
update
| Name | Value |
| Abstract | false |
| Leaf | false |
| Root | false |
| Documentation |
Update occurs when a model needs only a certain type of adjustment. This use case should use a specific XML update technique. The update procedure is triggered by the system itself in most of the cases. |
| Rank | Unspecified |
| Business Model | false |
| Unamed Generalization | |
| From |
admin
|
| Substitutable | false |
| Visibility | Unspecified |
search
| Name | Value |
| Abstract | true |
| Leaf | false |
| Root | false |
| Documentation |
The searching functions allow inspecting the properties of the PMML models in the repository. The search functions conform and therefore are limited to the information that a PMML model can incorporate according the PMML 3.2 specification. DeVisa provides searching functions such as:
Selecting the models with desired properties
Selecting the models that conform to a certain schema
This type of search is used especially as an extension to the scoring use care
Full text search in the model repository This type of search is useful when the client is looking for keywords in the description of the model, in the field names or field description, in the function type etc
Future work: create a search mechanism that allows more complex predicates on the search criterions. |
| Rank | High |
| Business Model | true |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Extend | |
| From |
scoring
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Condition | The client has specified the model through "Match" or "" case. |
| Unamed Extend | |
| From |
compose
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Unamed Extend | |
| From |
download
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Sequence Diagram/search | |
| Description | A complete search sequence diagram (also interaction with the client) |
| Type | Diagram |
scoring
| Name | Value |
| Abstract | true |
| Leaf | false |
| Root | true |
| Documentation |
The scoring use case means applying the models on the new instances. The scoring occurs via web service methods. Depending on the models, there are several types of DeVisa scoring procedures:
|
| Rank | High |
| Business Model | true |
| laxly specified model | |
| Documentation |
There are three ways in which a client application -a DM consumer that invokes a scoring method- requests a model in DeVisa.
Except for the first case, the model is laxly specified. |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Extend | |
| To |
search
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Condition | The client has specified the model through "Match" or "" case. |
| Unamed Generalization | |
| To |
classification scoring
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Generalization | |
| To |
clustering scoring
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Generalization | |
| To |
association rules scoring
|
| Substitutable | false |
| Visibility | Unspecified |
| Sequence Diagram/scoring | |
| Type | Diagram |
| Communication Diagram/scoring - Communications | |
| Type | Diagram |
classification scoring
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | The scoring method receives as input a set of instances and one or more classification models and classifies the instances with respect to the models. |
| Rank | High |
| Business Model | true |
| Unamed Generalization | |
| From |
scoring
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Communication Diagram/scoring - Communications | |
| Type | Diagram |
clustering scoring
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | The scoring method receives as input a set of instances and one or more clustering models and assigns the instances to the most appropriate cluster in each of the models. |
| Rank | Unspecified |
| Business Model | true |
| Unamed Generalization | |
| From |
scoring
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
| Sequence Diagram/scoring | |
| Type | Diagram |
association rules scoring
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | The scoring method receives as input a set of items (instances) and one or more association rule models. It determines all rules of each of the input models whose antecedent itemset is a subset of a the input itemset and returns the consequents of these rules as the inferred itemsets. An extension of this procedure computes all rules whose antecedent and consequent itemsets are included in the input itemset. This version is useful to determine which itemsets support which rules. |
| Rank | High |
| Business Model | true |
| Unamed Generalization | |
| From |
scoring
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
compose
| Name | Value |
| Abstract | true |
| Leaf | false |
| Root | true |
| Documentation |
Model Composition allows the combination of simple models into a single composite PMML model. PMML version 3.2 supports the combination of decision trees and simple regression models. More general variants would be possible and may be defined in future versions of PMML. In PMML Model composition uses three syntactical concepts
In DeVisa simple models can be combined into more complex ones forming new valid PMML documents. A client application can specify the models subject to composition and the combination method. DeVisa identifies the specified models. If the models do not exist in the repository then the process stops. The found models are checked for compatibility. If they are not compatible the process stops. The new valid model is returned to the user/stored in the repository. |
| Rank | High |
| Business Model | true |
| laxly specified models |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Extend | |
| To |
search
|
| Visibility | Unspecified |
| Stereotypes | Extend |
| Unamed Generalization | |
| To |
sequencing
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Generalization | |
| To |
selection
|
| Substitutable | false |
| Visibility | Unspecified |
sequencing
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation |
Model sequencing is the process through which two or more models are combined into a sequence where the results of one model are used as input in another model. Model sequencing is supported partially by the PMML specification. Examples of sequencing:
|
| Rank | Unspecified |
| Business Model | true |
| Unamed Generalization | |
| From |
compose
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
selection
| Name | Value |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation |
Model selection in PMML allows for combining multiple 'embedded models', aka model expressions, into the decision logic that selects one of the models depending on the current input values. Examples of selection
|
| Rank | Unspecified |
| Business Model | true |
| Unamed Generalization | |
| From |
compose
|
| Substitutable | false |
| Visibility | Unspecified |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
compare
| Name | Value |
| Abstract | true |
| Leaf | false |
| Root | true |
| Documentation |
A client application (DM Consumer) wants to compare two models. The client needs to specify:
Syntactic Comparison. Two PMML models are compared through a XML differencing approach. To be researched if the eXist's XML diff extension module can be used here. Semantic Comparison. Two models can be compared from the following points of view:
The Semantic comparison is useful for the cases in which the client envisions a model composition and wants to pre-check the compatibility of the models |
| Rank | Medium |
| Business Model | true |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Association | |||||||||||||||||
| From |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
statistics
| Name | Value |
| Abstract | true |
| Leaf | false |
| Root | true |
| Documentation |
An application can invoke this service to obtain statistics on the models. Example of statistics:
At the beginning DeVisa should be able to provide only a full report (PMQL) for the point (1). |
| Rank | Medium |
| Business Model | true |
| Unamed Include | |
| To |
authenticate
|
| Visibility | Unspecified |
| Stereotypes | Include |
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
DM Producer
| Name | Value |
| Visibility | public |
| Abstract | false |
| Leaf | true |
| Root | false |
| Documentation | The DM Producer is a WS client application -typically a DM application, like Weka- who uploads models in the DeVisa Repository. |
| Business Model | false |
| Unamed Association | |||||||||||||||||
| To |
|
||||||||||||||||
| Abstract | false | ||||||||||||||||
| Leaf | false | ||||||||||||||||
| Visibility | Unspecified | ||||||||||||||||
| Derived | false | ||||||||||||||||
DeVisa
| Name | Value |
| Abstract | false |
| Leaf | false |
| Root | false |
| Name | Documentation |
|
scoring
|
The scoring use case means applying the models on the new instances. The scoring occurs via web service methods. Depending on the models, there are several types of DeVisa scoring procedures:
|
|
compare
|
A client application (DM Consumer) wants to compare two models. The client needs to specify:
Syntactic Comparison. Two PMML models are compared through a XML differencing approach. To be researched if the eXist's XML diff extension module can be used here. Semantic Comparison. Two models can be compared from the following points of view:
The Semantic comparison is useful for the cases in which the client envisions a model composition and wants to pre-check the compatibility of the models |
|
compose
|
Model Composition allows the combination of simple models into a single composite PMML model. PMML version 3.2 supports the combination of decision trees and simple regression models. More general variants would be possible and may be defined in future versions of PMML. In PMML Model composition uses three syntactical concepts
In DeVisa simple models can be combined into more complex ones forming new valid PMML documents. A client application can specify the models subject to composition and the combination method. DeVisa identifies the specified models. If the models do not exist in the repository then the process stops. The found models are checked for compatibility. If they are not compatible the process stops. The new valid model is returned to the user/stored in the repository. |
|
authenticate
|
The WS client that invokes a certain method might need to be authenticated in order to execute the required function. |
|
admin
|
The Admin use case involves uploading/downloading the DeVisa models without any other processing. |
|
search
|
The searching functions allow inspecting the properties of the PMML models in the repository. The search functions conform and therefore are limited to the information that a PMML model can incorporate according the PMML 3.2 specification. DeVisa provides searching functions such as:
Selecting the models with desired properties
Selecting the models that conform to a certain schema
This type of search is used especially as an extension to the scoring use care
Full text search in the model repository This type of search is useful when the client is looking for keywords in the description of the model, in the field names or field description, in the function type etc
Future work: create a search mechanism that allows more complex predicates on the search criterions. |
|
classification scoring
|
The scoring method receives as input a set of instances and one or more classification models and classifies the instances with respect to the models. |
|
clustering scoring
|
The scoring method receives as input a set of instances and one or more clustering models and assigns the instances to the most appropriate cluster in each of the models. |
|
sequencing
|
Model sequencing is the process through which two or more models are combined into a sequence where the results of one model are used as input in another model. Model sequencing is supported partially by the PMML specification. Examples of sequencing:
|
|
selection
|
Model selection in PMML allows for combining multiple 'embedded models', aka model expressions, into the decision logic that selects one of the models depending on the current input values. Examples of selection
|
|
download
|
A DM Consumer can download a DeVisa model in order to use it internally, e.g import into the DM application. |
|
replace
|
Replace occurs when a model is replaced completely by a newer one. The new model will get the same model ID in the repository. |
|
upload
|
A DM Producer can upload models in the DeVisa repository via WS methods (SOAP, XMLRPC). |
|
statistics
|
An application can invoke this service to obtain statistics on the models. Example of statistics:
At the beginning DeVisa should be able to provide only a full report (PMQL) for the point (1). |
|
update
|
Update occurs when a model needs only a certain type of adjustment. This use case should use a specific XML update technique. The update procedure is triggered by the system itself in most of the cases. |
|
association rules scoring
|
The scoring method receives as input a set of items (instances) and one or more association rule models. It determines all rules of each of the input models whose antecedent itemset is a subset of a the input itemset and returns the consequents of these rules as the inferred itemsets. An extension of this procedure computes all rules whose antecedent and consequent itemsets are included in the input itemset. This version is useful to determine which itemsets support which rules. |